Title of paper under discussion
Musician advantage for speech-on-speech perception
Authors
Deniz Başkent and Etienne Gaudrain
Journal
The Journal of the Acoustical Society of America 139, EL51 (2016)
Link to original paper (open access)
Overview
Are musicians better than non-musicians at being able to listen to one human talking whilst hearing two? It is a skill that may benefit from better pitch perception, better ‘stream segregation’ (the ability to separate incoming sounds into separate streams of information), better attention etc – all qualities that musical training might be expected to improve. This research, carried out in Holland, found that musicians were indeed better at perceiving speech in the presence of another talker – and that their skill at this relied on ‘higher’ cognitive processes rather than merely better pitch perception.
Background – “streaming”, “masking” and “vocal tract length”
Musicians have often been found to be better at auditory perceptual tasks. This could be down to “better processing of acoustic features” (features such as the fundamental frequency, or F0, of a note – for example 440 Hz in the case of A below middle C). Or it could be down to better auditory attention, more extended auditory working memory capacity, or “better stream segregation”.
Stream segregation, described by leading music psychologist Diana Deutsch (in her landmark book “Musical Illusions and Phantom Words”) as the ability to identify and group sounds into “unified streams of information so that we can focus attention on one of them while others are relegated to the background”, is a crucial musical tool. Visual information is streamed too – Deutsch gives the example of the famous picture by Danish artist Edgar Rubin:

Is it two faces or is it a vase? It depends how the brain “streams” the information, and it can’t be perceived as both at the same time.
Deutsch gives two musical examples of stream segregation. In the first example the listener hears the two streams of music, or “parallel melodies”, according to their pitch proximity:

And in Deutsch’s second example a “single pitch is repeatedly presented in the lower range, and this forms a ground against which the melody in the upper range is perceived”:

Now, returning to our Dutch research paper… the scientists were keen to know if a musician’s enhanced auditory skills (at pitch perception, streaming etc) would help them in picking out speech. This brings us to the concept of “masking”.
“Masking” – the phenomenon whereby one stream of information interferes with another, or “masks” it, comes in two forms: 1) “energetic masking” where the energy (e.g. loudness) of one stream overcomes the other and 2) “informational masking” where similarity of information in one stream compared to another confuses the listener, meaning again that one stream is being masked by the other.
Previous research suggests that when speech is masked by (non-vocal) background noise, the masking effect of that background noise depend on its strength, i.e. energetic masking. In contrast, when speech is masked by another speaker (as in this project), the masking effect is dependent on the difference in pitch between the two speakers and on informational (rather than energetic) masking. This makes speech-on-speech (compared with speech-on-noise) a more likely contender for “musician advantage” when it comes to intelligibility.
The research team therefore set out to see if musicians had an advantage over non-musicians at discerning speech-on-speech; and if so, to see if that advantage was due to the difference in pitch between the two speakers.
One more piece of background. The ‘pitch’ of a speaker can be down to two things: 1) the “fundamental frequency” (“F0”) of the voice, and 2) the “vocal tract length” (“VTL”) of the speaker. This is because there is a rich variety of harmonics (on top of the fundamental frequency) in any given voice, and the shape and size of the vocal tract length “celebrates” certain of these harmonics over others by allowing them to achieve resonance. (For more detail see this explanation from the website “www.voicescienceworks.org”). Therefore the scientists in this project manipulated the pitches of the voices by semitones, either by adjusting their average F0 or their VTL, to see which kind of pitch difference (if either) between the two voices helped musicians focus on one of those two voices.
Method
38 participants (18 musicians, 20 non-musicians) were presented with a series of tests each consisting of two different simultaneous digital audio recordings of spoken sentences, a ‘target sentence’ and a slightly louder ‘masker sentence’. (The target sentence always started half a second after the masker sentence). The difference in the average voice pitches of the target and masker sentences were created by variously manipulating the voice characteristics ‘F0’ (shifted up by 0,4, or 8 semitones) and ‘VTL’ (shifted down by 0, 0.75 or 1.5 semitones).
The participants were given scores according to how many words of the target sentences were correctly identified.
Results
The results chart below illustrates the intelligibility score (percentage of correctly identified words) with relation to the various pitch differences and the different groups (musicians/non-musicians).
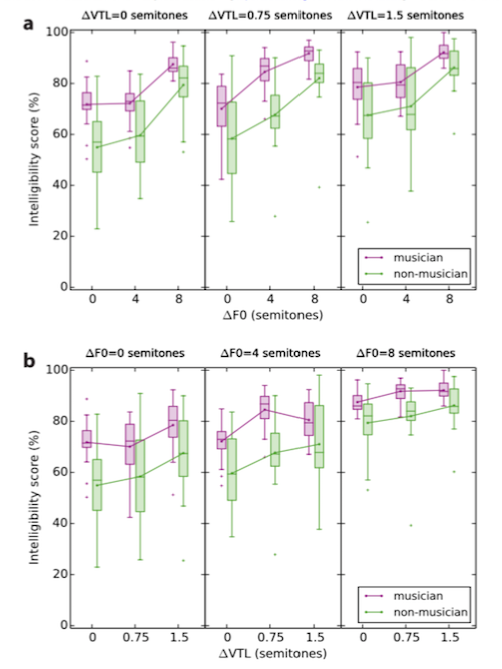
It’s clear that across the board the musicians (in purple) were significantly better than non-musicians (in green) at discerning target sentences in the presence of masking sentences. But the musician advantage didn’t increase as the pitch differences increased (either the F0 for the VTL), and in fact musicians demonstrated their biggest advantage when the average pitch difference between the two speakers was zero (left-most graphs, top and bottom).
Discussion
Average pitch difference per se was not the factor giving musicians their advantage; if it had been, the bigger that difference the greater would have been the advantage. Indeed the greatest advantage was on display when average F0 difference between the two sentences was zero. However even when the average F0 difference is zero, the instantaneous F0 difference may not be, because “the prosodic F0 contours of the concurrent voices differed”. The researchers suggest that the “musician advantage could thus also be derived from an enhanced ability to process and disentangle fast changing F0 differences”, a higher level cognitive function than mere pitch perception.
The scientists conclude that “perhaps the strong speech-on-speech perception advantage observed with musicians is not a direct result of better pitch perception, but instead more associated with other factors related to auditory perception, such as better stream segregation, better rhythm perception, or even better auditory cognitive abilities”.
Coda
Georg Philipp Telemann – Recorder Sonata in C TWV 41: c5
Hans Martin Linde – recorder, Johannes Koch – viola da gamba, Hugo Ruf – harpsichord